Resources / Blog
SpecMap: Connecting Datasheets to Code
H2LooP's SpecMap provides AI-powered traceability between datasheet specifications and code implementations for embedded systems, IoT devices, and standards-compliant software.
SpecMap: Connectiong Datasheets to Code
The Problem
Systems engineering faces a fundamental challenge in establishing precise mapping between datasheet specifications and code implementations. This problem is particularly acute in systems-level software development, including embedded systems, IoT devices, and standards-compliant implementations, where understanding the relationship between specification documents and actual code becomes essential for maintenance, verification, and development processes.
A typical systems software project involves 200-page datasheets describing communication protocols, register definitions, and initialization sequences, with corresponding implementations spanning thousands of files across complex directory hierarchies. Manual mapping does not scale. Repositories contain complex folder hierarchies, hundreds of C/C++ files, and thousands of functions, macros, and structs scattered across the codebase. Locating which code implements which specification section becomes a time-consuming process.
This creates significant challenges: new team members face steep learning curves in understanding system architecture, compliance verification requires extensive manual audits, and tracking specification changes across the codebase becomes increasingly difficult as systems evolve. The disconnect between datasheet specifications and code implementations creates tangible problems: maintenance complexity increases, knowledge transfer slows, and ensuring specification compliance demands substantial manual effort.
Why Current Solutions Fall Short
We explored several existing approaches before building SpecMap, and each revealed fundamental limitations in how we think about specification-to-code mapping.
Traditional Text-Based Search (grep/mgrep)
The most straightforward approach is keyword matching. Tools like mgrep extract key terms from specification sections and search for those patterns across repository files.
The fundamental limitation: grep performs syntactic matching without semantic understanding. A search for "NCI interface initialization" returns every file containing those words, regardless of context. The approach cannot distinguish between initialization code that sets up the system at startup and runtime logic that handles NCI interface operations during execution. This results in high false positive rates where keyword matches are technically correct but functionally irrelevant.
In testing, grep-based methods achieved 100% file existence accuracy (only returning files that actually exist) but 0% file mapping accuracy (none of those files were correct for the specification). These methods locate code containing relevant keywords but serving entirely different purposes.
BM25 + Vector Embeddings Approach
To address grep's semantic limitations, a more sophisticated hybrid approach was developed combining BM25 keyword ranking with vector embeddings for semantic similarity.
This hybrid approach combines BM25 (probabilistic keyword ranking) with vector embeddings (semantic similarity) in a two-stage pipeline: BM25 pre-filters candidates based on keyword relevance, then vector search refines them based on semantic meaning. The approach is computationally efficient and captures relationships that grep completely misses.
However, critical weaknesses remained. Vector averaging across multiple technical concepts diluted semantic coherence—when initialization, interface management, and protocol handling are combined into a single embedding, the averaged representation loses precise meaning. The system locates code that is topically related but functionally inappropriate.
More importantly, this approach treats all code symbols as equivalent entities in a flat search space. It has no concept of repository structure, folder organization, or architectural layers. When searching for service-level initialization functions, the system may return low-level I2C hardware configuration code. Both relate to "initialization," but they operate at completely different abstraction levels in the software architecture.
In evaluation, BM25 + embeddings also achieved 100% file existence accuracy but 0% file mapping accuracy. While it improved semantic understanding over grep, without hierarchical context, it could not identify architecturally appropriate implementations.
The Core Problem
All these approaches share a fundamental flaw: they attempt direct specification-to-code mapping without understanding software hierarchy. Code organization reflects architectural layers, separated concerns, and grouped functionality. Ignoring this organization means ignoring crucial context that determines whether a match is correct.
The SpecMap Approach: Hierarchical Decomposition
SpecMap addresses this challenge through hierarchical decomposition that respects software architecture. Instead of attempting direct specification-to-code mapping, the methodology decomposes the problem into manageable steps.

Step 1: Folder Discovery
The first step identifies which folders in the repository are likely to contain relevant implementations. For specifications about NFC services, the system examines the service layer. For hardware initialization, it checks HAL implementation folders.
LLM-based analysis understands repository structure and generates comprehensive documentation of folder contents. The system analyzes folder organization and maps specification requirements to architectural components, dramatically narrowing the search space before examining individual files. This architectural awareness is what grep and BM25 approaches fundamentally lack.
Step 2: File Discovery
Within relevant folders, the system determines which specific files contain implementations. On-demand structure documentation is generated for each folder, creating detailed descriptions of each file's purpose and functionality. This goes beyond listing filenames—it understands what each file does in the context of the system architecture.
This step pinpoints exactly where implementations should be located, not just where related keywords appear. By understanding file roles within their architectural context, the approach avoids the false positives that plague keyword-based methods.
Step 3: Code Symbol Discovery
At this level, the system extracts specific code symbols from relevant files. Using Universal Ctags, a robust static analysis tool for C/C++ code, all code symbols are extracted: functions, macros, structs, constants, enums, and typedefs.
This is crucial for systems-level software. While traditional tools focus only on functions, systems software relies heavily on preprocessor macros for hardware abstraction, configuration constants for system parameters, and data structures for protocol definitions. Missing these artifacts means missing critical implementation components.
Automated code summarization creates compact representations that preserve key elements while significantly reducing the text the LLM processes. This makes the approach scalable to large codebases.
Step 4: Validation & Gap Analysis
Finally, the complete mapping is validated through sequential processing that maintains context across specification sections. This step determines implementation status for each section: fully implemented, partially implemented, not implemented, or not applicable to the codebase.
This validation provides gap analysis for compliance verification and development planning. Beyond finding what exists, it identifies what is missing relative to the specification, transforming SpecMap from a discovery tool into a comprehensive compliance verification system.
The hierarchical decomposition is key: each step restricts the search space for subsequent steps, making the approach both faster and more accurate than direct mapping. By respecting the natural hierarchy of software architecture, context at each level improves decisions at the next level.
Experimental Results and Methodology Evolution
SpecMap was evaluated on multiple open-source systems software repositories with manually curated ground truth. The methodology evolved through iterative development, with each iteration addressing specific limitations.
The Evolution: Five Iterations
| Iteration | Key Addition | Runtime | Tokens | Accuracy | Key Insight |
|---|---|---|---|---|---|
| 1 | Baseline Gemini | 90 min | 68.8M | 53.3% | Need structure |
| 2 | + Structures | 21 min | 49M | 63.3% | Context eliminates exploration |
| 3 | + Ctags | 24 min | 17.7M | 56.7% | Compact representation scales |
| 4 | + Qwen3 | 10 min | 3.2M | 66.7% | Domain-specific wins |
| 5 | + Validation | 18 min | 10.9M | 73.3% | Quality over speed |
Iteration 1: Baseline Gemini Approach
Direct LLM-based mapping using Gemini 2.5 Flash without structural documentation or specialized code parsing. While achieving 53.3% accuracy, the 90-minute runtime and 68.8M token consumption revealed the cost of exploratory analysis—the LLM had to discover repository organization from scratch. This established the need for structural context.
Iteration 2: Added Repository/Folder/File Structures
Generated comprehensive structure documentation to provide architectural context upfront. This produced the most significant runtime improvement (76.7% reduction to 21 minutes) by eliminating exploratory analysis. The LLM could now make informed decisions about where to look, improving file mapping accuracy to 63.3%. Token consumption dropped to 49M as redundant exploration was eliminated.
Iteration 3: Integrated Ctags for Code Parsing
Added Universal Ctags for reliable symbol extraction and automated code summarization. This achieved the largest token reduction (63.8% to 17.7M tokens) by replacing full source file processing with structured symbol information. Runtime increased slightly to 24 minutes due to parsing overhead, but the token savings made the approach significantly more scalable. File mapping accuracy dipped to 56.7%, indicating the need for better validation.
Iteration 4: Switched to Qwen3-Coder Model
Transitioned from Gemini 2.5 Flash to Qwen3-Coder-30B-A3B-Instruct-FP8. This significantly improved efficiency with 58.3% runtime reduction (to 10 minutes) and 81.9% token reduction (to 3.2M tokens). The substantial reduction is partly attributed to switching from Gemini 2.5 Flash, which is a thinking model involving internal reasoning processes, to Qwen3. File mapping accuracy improved to 66.7%, and confidence calibration became more realistic (84.1% vs 90.1%), as the earlier Gemini-based approaches exhibited inflated confidence scores.
Iteration 5: Added Sequential Validation (Final Methodology)
Introduced validation that processes mappings sequentially, maintaining context across specification sections and performing rigorous gap analysis. While adding controlled overhead (80% runtime increase to 18 minutes), this achieved the highest file mapping accuracy at 73.3% and 95.9% file existence accuracy. Token consumption increased to 10.9M tokens, but the quality improvements justify the cost. This transforms the system from discovery to comprehensive analysis, identifying not just implementations but also gaps and validation status.
Comprehensive Performance Comparison
| Method | Confidence (%) | Elements per Section | Runtime (min) | Tokens (M) | File Exist. (%) | File Map. Acc. (%) |
|---|---|---|---|---|---|---|
| mgrep | N/A | N/A | N/A | N/A | 100.0 | 0.0 |
| BM25 | N/A | N/A | N/A | N/A | 100.0 | 0.0 |
| Gemini* | 89.5 | 19.0 | 90 | 68.8 | 92.7 | 53.3 |
| Gemini* + H2LooP Toolchain (Structures) | 90.4 | 15.9 | 21 | 49.0 | 93.3 | 63.3 |
| Gemini* + H2LooP Toolchain (Structures + Ctags) | 90.1 | 16.4 | 24 | 17.7 | 95.3 | 56.7 |
| Qwen3** + H2LooP Toolchain (Structures + Ctags) | 84.1 | 11.6 | 10 | 3.2 | 96.3 | 66.7 |
| Proposed (Full) | 83.1 | 9.1 | 18 | 10.9 | 95.9 | 73.3 |
*Gemini 2.5 Flash
**Qwen3-Coder-30B-A3B-Instruct-FP8
Key Observation: Statistical approaches (mgrep, BM25) achieve 100% file existence but 0% mapping accuracy—they find files that exist but are functionally wrong. The hierarchical approach achieves 73.3% mapping accuracy by understanding architectural context.
Visual Performance Analysis
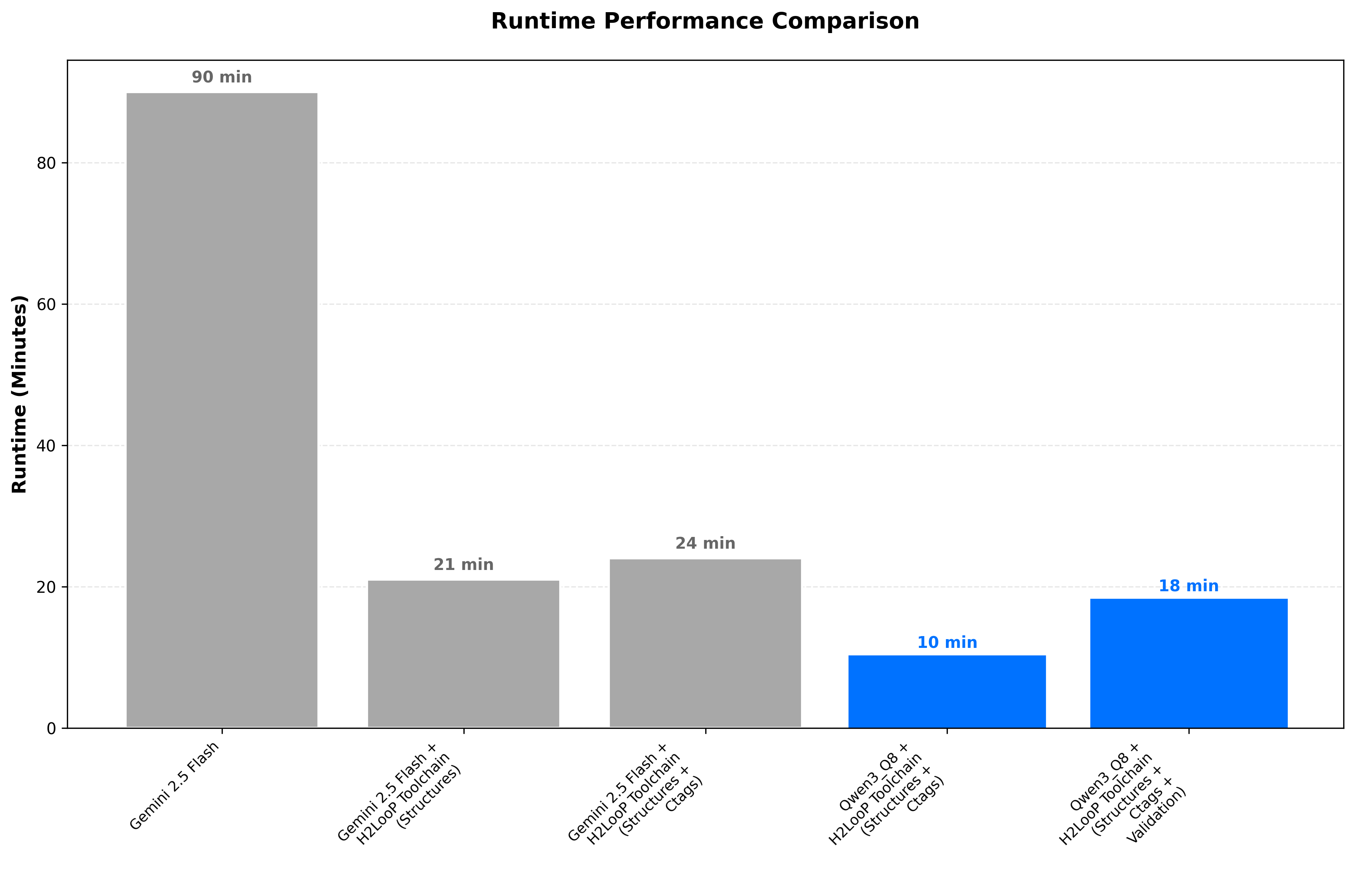
The runtime progression shows the dramatic impact of structural documentation (Iteration 2) and model selection (Iteration 4), with controlled overhead from validation (Iteration 5) that delivers quality improvements.
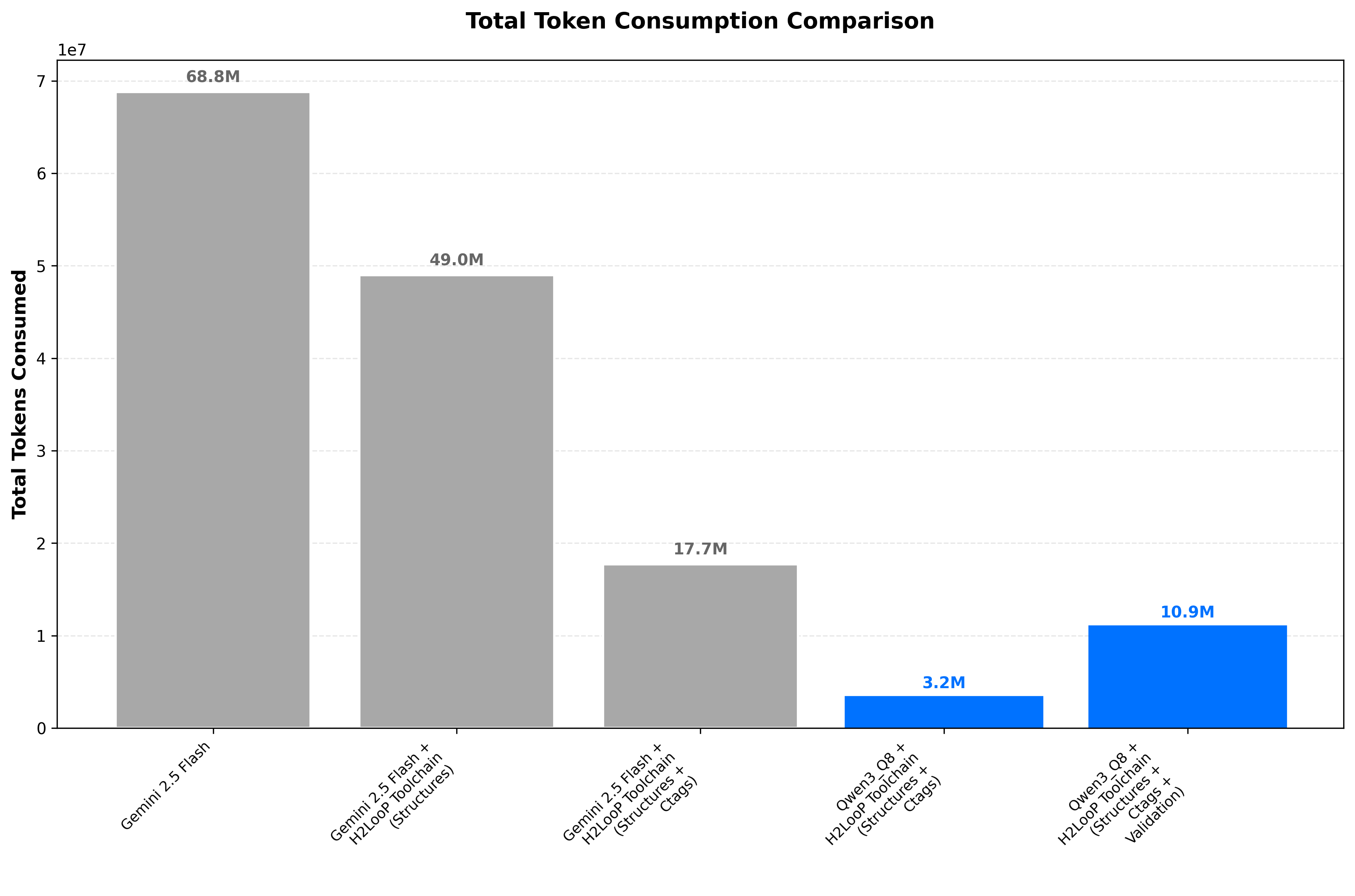
Token consumption follows a similar pattern, with the most significant reductions coming from structural context (Iteration 2) and Ctags integration (Iteration 3). The final methodology achieves 84% reduction compared to the baseline.
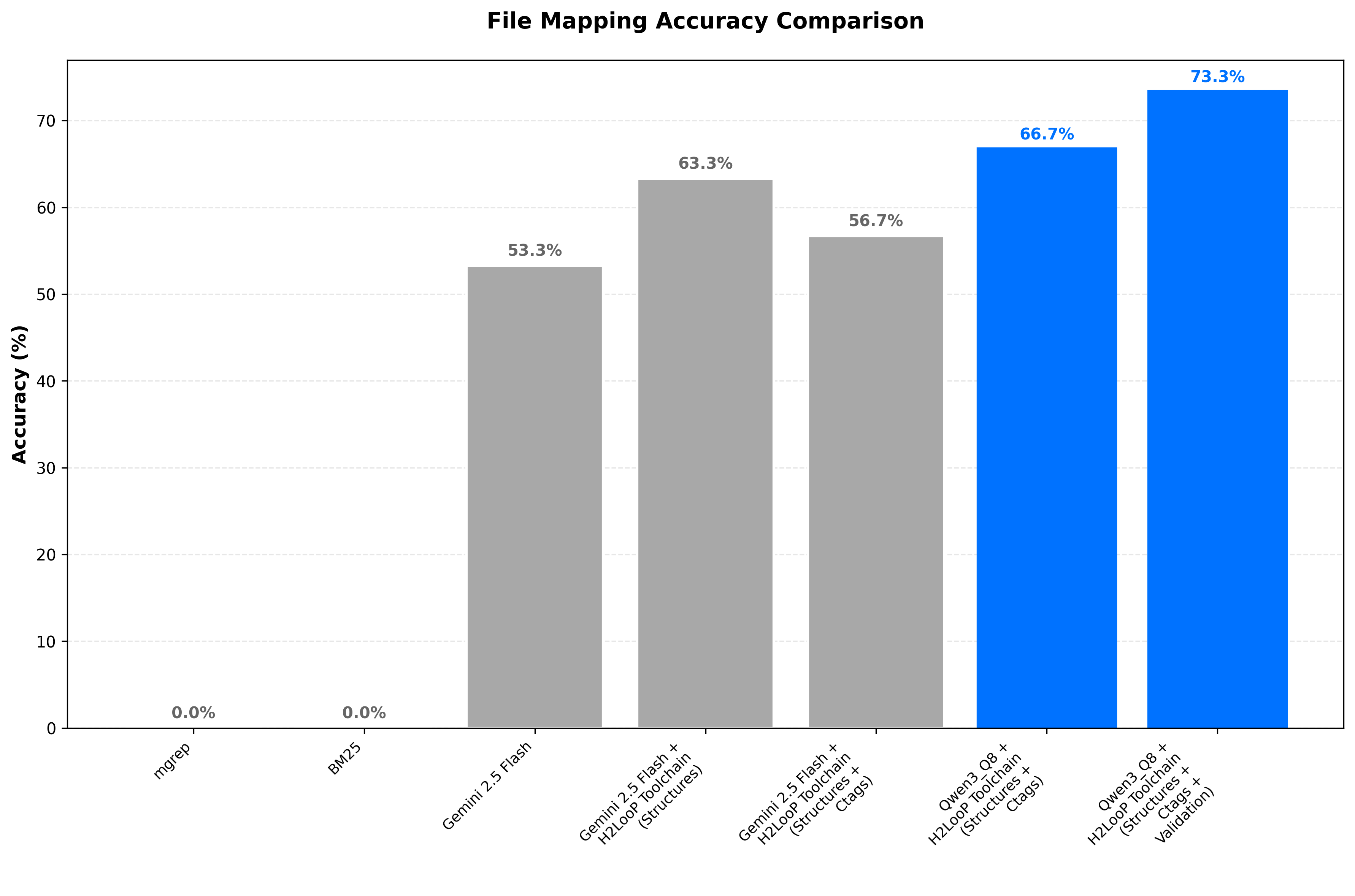
File mapping accuracy shows steady improvement through the iterations, with the final validation step (Iteration 5) achieving the highest accuracy at 73.3%. Statistical approaches (mgrep, BM25) achieve 0% mapping accuracy despite perfect file existence—they find files that exist but are functionally wrong.
Key Takeaways
- 80% faster processing: From 90 minutes to 18 minutes for complete analysis
- 84% reduction in computational overhead: From 68.8M to 10.9M tokens
- 73.3% file mapping accuracy: Correctly identifying the right files for each specification
The iterative development process revealed that the combination of structural context, efficient code parsing, appropriate model selection, and rigorous validation is essential for accurate specification-to-code mapping. Each component addresses a specific limitation, and together they create a system that is both efficient and accurate.
Real-World Impact and Future Directions
SpecMap addresses practical challenges in systems software development while enabling new possibilities for the field. For teams building safety-critical systems in automotive, aerospace, or medical devices, the methodology enables systematic specification compliance verification, identifying missing implementations with precise granularity and tracing requirements from high-level specifications to specific code symbols. New developers joining systems software projects can accelerate understanding of system architecture through comprehensive mappings, while legacy systems benefit from reconstructed relationships between intended functionality and actual implementation.
The approach opens new possibilities: real-time compliance monitoring in CI/CD pipelines, automated specification adherence verification during development, and sophisticated code understanding systems that combine structural decomposition with learned patterns. The systematic mappings also create high-quality training datasets that capture semantic relationships between natural language descriptions and code artifacts, enabling more accurate AI systems for automated code analysis.
For systems software teams, this means less time hunting through code and more time building features. For organizations with compliance requirements, it means systematic verification instead of manual audits. For the broader software engineering community, it demonstrates that thoughtful decomposition combined with modern AI can solve problems that seemed intractable with traditional approaches.
For complete technical details, methodology, and evaluation results, see the full research paper: SpecMap: Hierarchical LLM Agent for Datasheet-to-Code Traceability Link Recovery in Systems Engineering